Philosophy¶
tf-transformers is designed primarily for industrial research. Rather than showing dummy tutorials to enhance the concept, all the tutorials and design philosophy focus on making life of researchers east with standard tools. Our aim is to help Deep Learning practitioners to pretrain , fine-tune and infer a models with maximum ease and knowledge.
NLP researchers and educators seeking to use/study/extend large-scale transformers models
hands-on practitioners who want to fine-tune those models and/or serve them in production
engineers who just want to download a pretrained model and use it to solve a given NLP task.
The library was designed with two strong goals in mind:
Be as easy and fast to use as possible:
We strongly limited the number of user-facing abstractions to learn, in fact, there are almost no abstractions, just three standard classes required to use each model: configuration, models .
All of these classes can be initialized in a simple and unified way from pretrained instances by using a common
from_pretrained()instantiation method which will take care of downloading (if needed), caching and loading the related class instance and associated data (configurations’ hyper-parameters, tokenizers’ vocabulary, and models’ weights) from a pretrained checkpoint provided on Hugging Face Hub or your own saved checkpoint.On top of those three base classes,
Trainerto quickly train or fine-tune a given model.As a consequence, this library is NOT a modular toolbox of building blocks for neural nets. If you want to extend/build-upon the library, just use regular Python/TensorFlow/Keras modules and inherit from the base classes of the library to reuse functionalities like model loading/saving.
Provide state-of-the-art models with performances as close as possible to the original models:
We provide at least one example for each architecture which reproduces a result provided by the official authors of said architecture.
The code is written in pure Tensorflow 2.0 and most models supprt TFlite models also.
Main concepts¶
The library is built around three types of classes for each model:
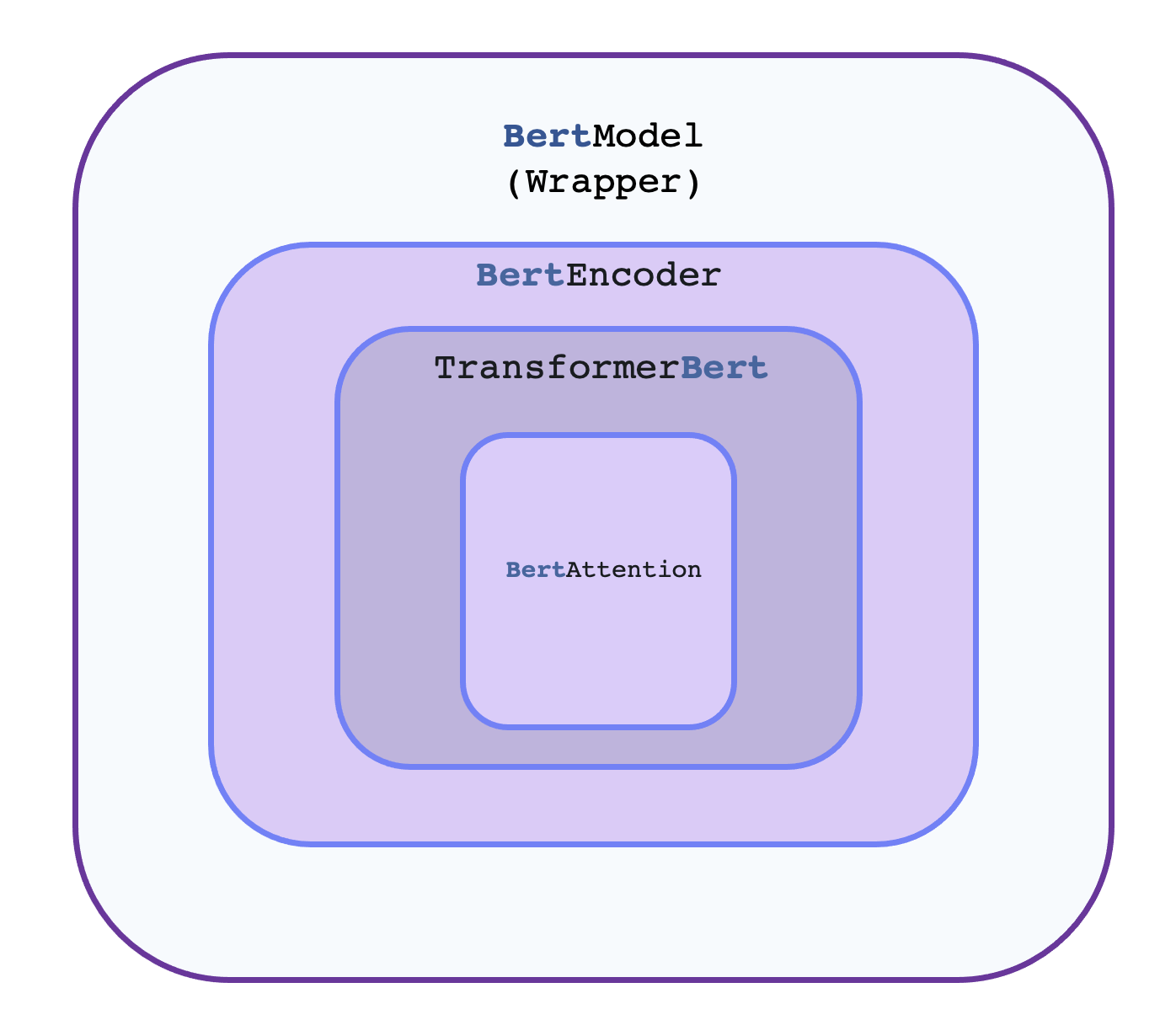
Model classes such as
BertEncoder. The hierarchical flow remains the same for all or most models. The core architectural implementations is happening insideBertEncoder. Every encoder hasTransformerBertand corresponding attention implementationsMultiHeadAttention.Configuration classes such as
BertConfig, which store all the parameters required to build a model. You don’t always need to instantiate these yourself. In particular, if you are using a pretrained model without any modification, creating the model will automatically take care of instantiating the configuration (which is part of the model).Tokenizer classes such as
AlbertTokenizer, which store the vocabulary for each model and provide methods for encoding/decoding strings in a list of token embeddings indices to be fed to a model. This is a faster implementation based on tensorflow-text.All encoders can be used as decoder with one argument
use_decoder=True.
All these classes can be instantiated from pretrained instances and saved locally using two methods:
from_pretrained()lets you instantiate a model/configuration/tokenizer from a pretrained version either provided by the library itself (the supported models are provided in the list here) or stored locally (or on a server) by the user,save_checkpoint()lets you save a model/ as tensorflow checkpoints.save_transformers_serialized()lets you save a model/ as tensorflow saved models.